Are we expecting too much from AI? According to data from S&P Global, "the percentage of companies abandoning the majority of their AI initiatives before they reach production has surged from 17% to 42% year over year." As experimentation deepens, developers are beginning to draw clearer lines between where AI excels and where it still falls short.
Consider the sprawling codebases typical of mature companies. For LLMs to understand complex systems and propose changes across many files, they require a long context window — the amount of text or code that a model can process when prompted. Coding agents often struggle when projects become large or interconnected.
Some hope that newer models and better context management can bridge the gap to better code suggestions. Claude Sonnet 4 achieves a score of 72.7% on SWE-bench Verified, a benchmark for performance on software engineering tasks, when tested for its agentic coding capabilities. Other tools, like Sourcegraph Amp, provide LLMs with better context in each prompt and pull information from multiple apps, such as Jira and Slack.
But developer opinion can swing wildly for AI coding tools. Both GitHub Copilot and Windsurf have seen their average rating in the Visual Studio Code marketplace fluctuate from near perfect to middling. For all the technical advancements in AI, why is developer satisfaction sometimes so mixed?
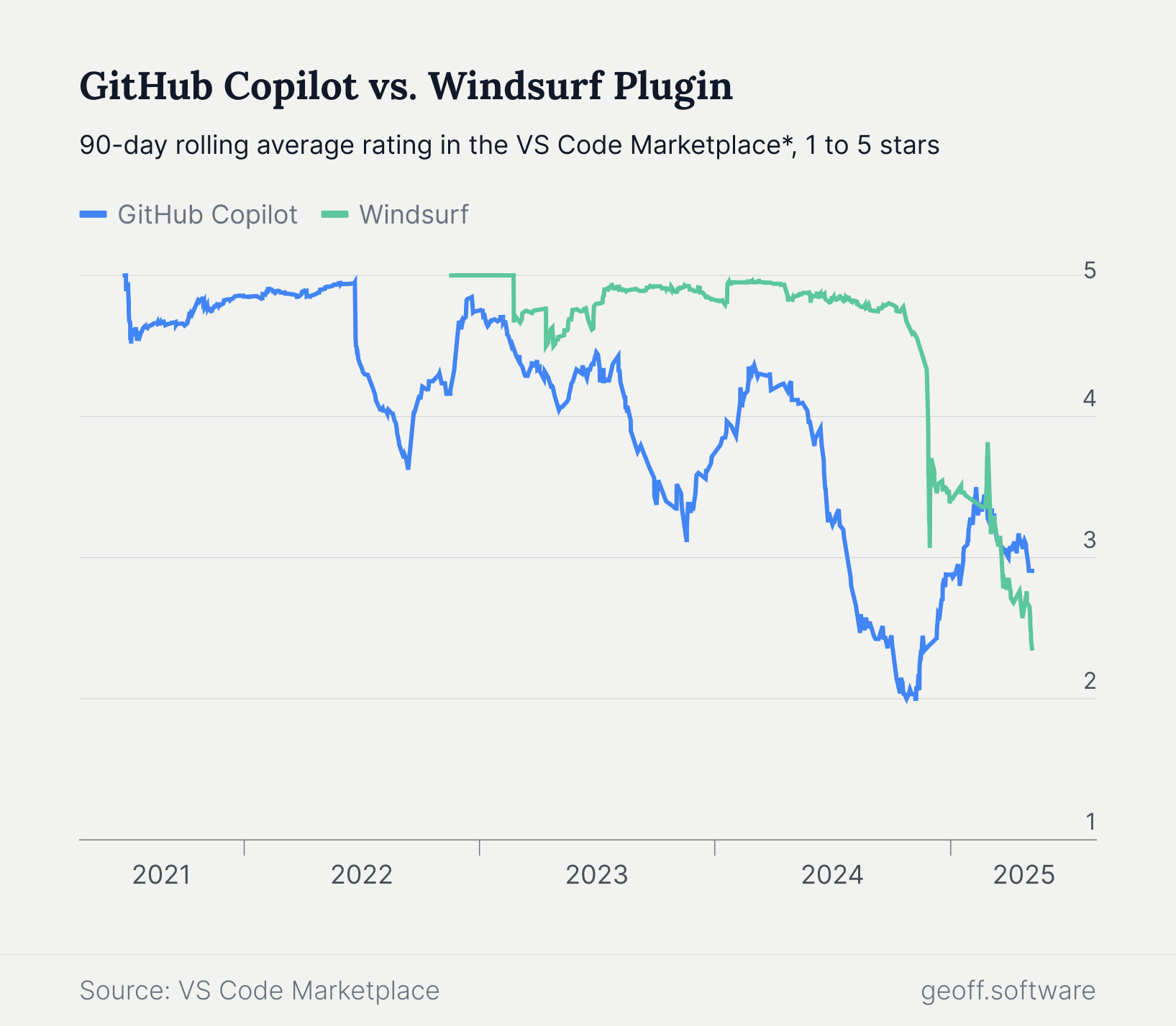
Developer satisfaction is important to measure—but it's often a lagging indicator. While it reflects how developers feel using AI tools, it doesn’t reveal how to improve their experience in the future. Many factors, including those beyond technical requirements, shape their perception. Models and context matter, but so do user-friendly workflows and clean user interfaces.
One area for improvement often overlooked is developer training. Without guidance on prompting techniques or best practices, developers may struggle to get value from large language models or AI agents. These practices can vary widely by team, language, and experience level. Companies that overlook this nuance—and fail to invest in meaningful experimentation and training—risk seeing their AI tools dismissed before their potential is fully realized.
The result is a cycle of volatile ratings and polarizing discussion—even as models and tools make real progress. Initial euphoria gives way to frustration, then cautious appreciation. And with each new release or feature, the cycle begins anew.
To make matters more challenging for toolmakers, developers aren’t shy about trying multiple tools—often side by side. Switching is easy, and code is portable, so if one agent falls short, another can quickly take its place. That flexibility benefits developers, but it makes winning an uphill battle for AI tool providers.